A. See (2017) – Get to the point
- Dataset: CNN/DM
- Implementation: https://github.com/abisee/pointer-generator/
- Results:
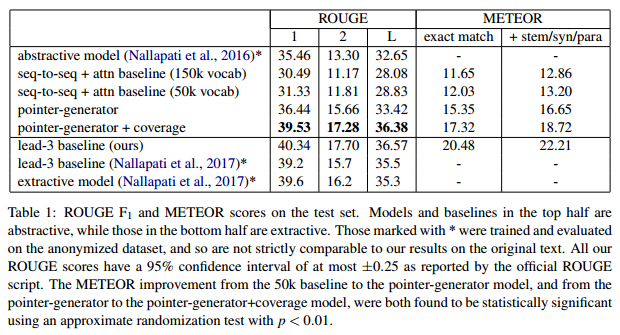
Model
- Attention over source:
- Attention scores: \[ e_i^t = v^T tanh(W_h h_i + W_s s_t + b_{attn}) \]
- Normalized scores: \[ a^t = softmax(e^t) \]
- Context vectors: \[ h_t^* = \sum_i{a_i^th_i} \]
- Probabilities over the vocabulary: \[ P_{vocab}= softmax(V’(V[s_t, h_t^*]+b)+b’) \]
- Loss: \[ loss_t = -log P(w_t^*) \]
- Pointer-Generator mechanism:
- Soft-switch: \[ p_{gen} = \sigma(w_{h^{\ast}}^T h_t^{\ast}+ w_s^T s_t+w_x^T x_t + b_{ptr}) \]
- Probabilities becomes: \[ P(w) = p_{gen}P_{vocab}(w)+(1-p_{gen})\sum_{i:w_i=w}{ai^t} \]
- Coverage loss:
- coverage vector: \[ c^t = \sum_{t’=0}^{t-1}{a^{t’}} \]
- attn_scores: \[ e_i^t = v^Ttanh(W_h h_i+W_s s_t+w_c c_i^t + b_{attn}) \]
- coverage loss: \[ covloss_t = \sum_t min(a_i^t, c_i^t) \]
- Final loss: \[ loss_t = -log{P(w_t^*})+\lambda\sum_t{min(a_i^t, c_i^t)} \]
Paulus (2017) – A Deep Reinforcement Model for Abstractive Summarization
- Dataset: CNN/DM & NYT
- Implementation: no official. WIP.
- Results:
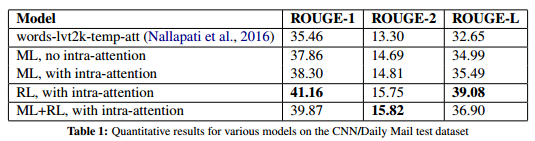
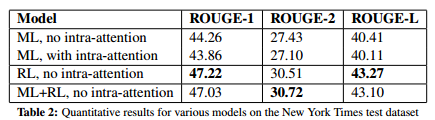
Model
- Intra-attention Model
- attn scores: \[ e_{ti} = {h_t^d}^T W_{attn}^e h_i^e \]
- temporal scores:
\[
e^\prime_{ji} =
\begin{cases}
exp(e_{ti}) & \text{if } t=1\\
\frac{exp(e_{ji})}{\sum_{j=1}^{t-1}{exp(e_{ji})}} & \text{otherwise} \end{cases} \] -
normalized attn scores: \[ \alpha_{ti}^e = \frac{e^\prime_{ti}}{\sum_{j=1}^{n}{e_{tj}^\prime}} \]
- context vector: \[ c_t^e = \sum_{i=1}^{n}{\alpha_{ti}^e h_i^e} \]
- Intra-decoder attention:
- \[ e_{tt^\prime}^d = {h_t^d}^T W_{attn}^e h_{t^\prime}^d \]
- \[ \alpha_{tt^\prime}^d = \frac{e^d_{tt^\prime}}{\sum_{j=1}^{t-1}{e_{tj}^d}} \]